
在AMD 780M GPU上运行Ollama
Ollama 是一个开源框架,主要用于在本地运行大型语言模型。它具有以下特点:
支持多种模型:如 Llama 2、Code Llama、Mistral、Gemma 等,并允许用户根据特定需求定制和创建自己的模型。
简化部署过程:将模型权重、配置和数据捆绑到一个包中,优化了设置和配置细节,包括 GPU 使用情况。
多平台支持:支持 macOS、Linux 平台,Windows 平台的预览版也已发布。
提供 REST API:默认提供了一个 REST API 端口,允许用户通过 API 调用和管理模型。
但 Ollama 并不支持 AMD 780M 核显,这主要是因为其框架和优化主要针对 NVIDIA 的 CUDA 技术进行开发。CUDA 是 NVIDIA 推出的并行计算平台和编程模型,广泛应用于深度学习和高性能计算领域。由于 CUDA 提供了丰富的开发工具、库和广泛的社区支持,Ollama 的开发者选择了专注于利用 CUDA 的优势来优化性能和兼容性,目前官方提供支持的AMD显示核心如下:
"gfx900" "gfx906:xnack-" "gfx908:xnack-" "gfx90a:xnack+" "gfx90a:xnack-" "gfx940" "gfx941" "gfx942" "gfx1010""gfx1012" "gfx1030" "gfx1100""gfx1101" "gfx1102"AMD 780M的显示核心代号为gfx1103,不在上面的支持列表中,不过github上有大佬开源了魔改版的ollama windows安装包可以直接使用,目前最新版本为v0.2.8,经测试在AMD7840HS机型上能正常使用,可正常调度AMD 780M GPU。
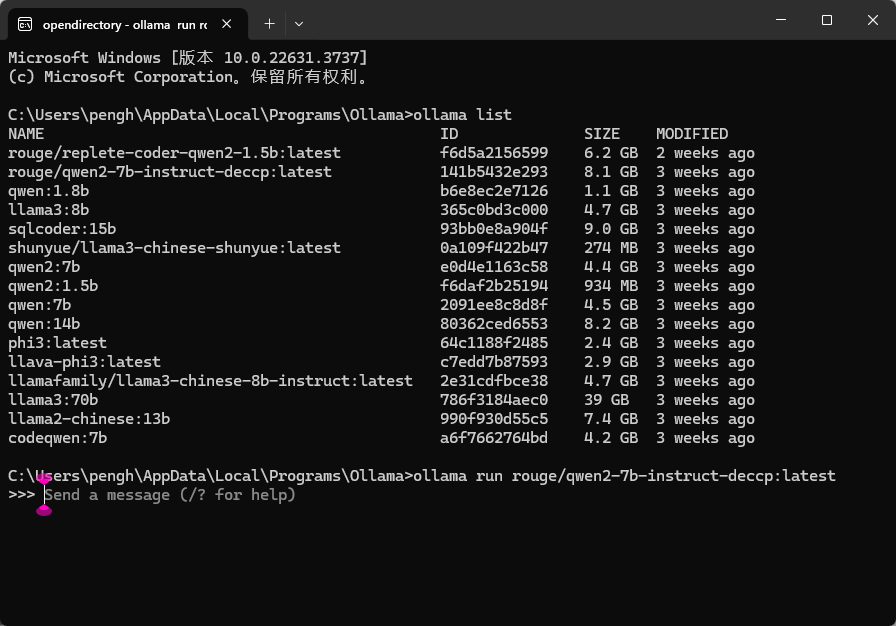
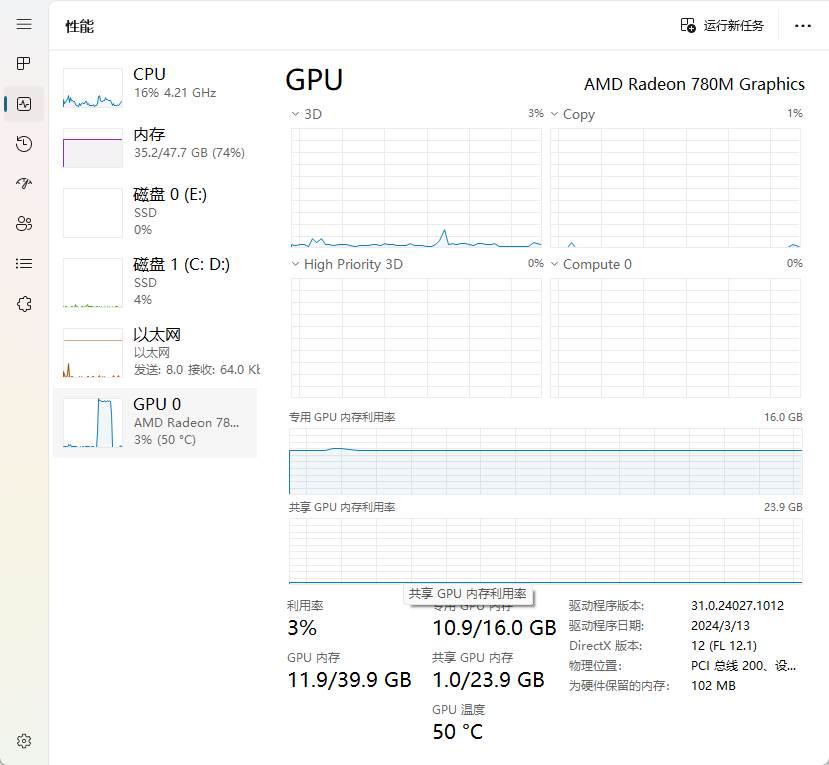
原项目地址为:https://github.com/likelovewant/ollama-for-amd
阿里云盘:
https://www.alipan.com/s/6vMNmEfbZGz 提取码: l66m
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 程序员小航
